

Google trained us to make short queries, click on the first result, and move on. That habit hurts us when using LLMs.
The primary interface to LLMs looks like this, and everyone is building it the same. Yes, LLMs have APIs but for most of us trying to leverage the most powerful technology since fire, this interface blocks, shrinks, constrains, filters, mangles what we can do with it.
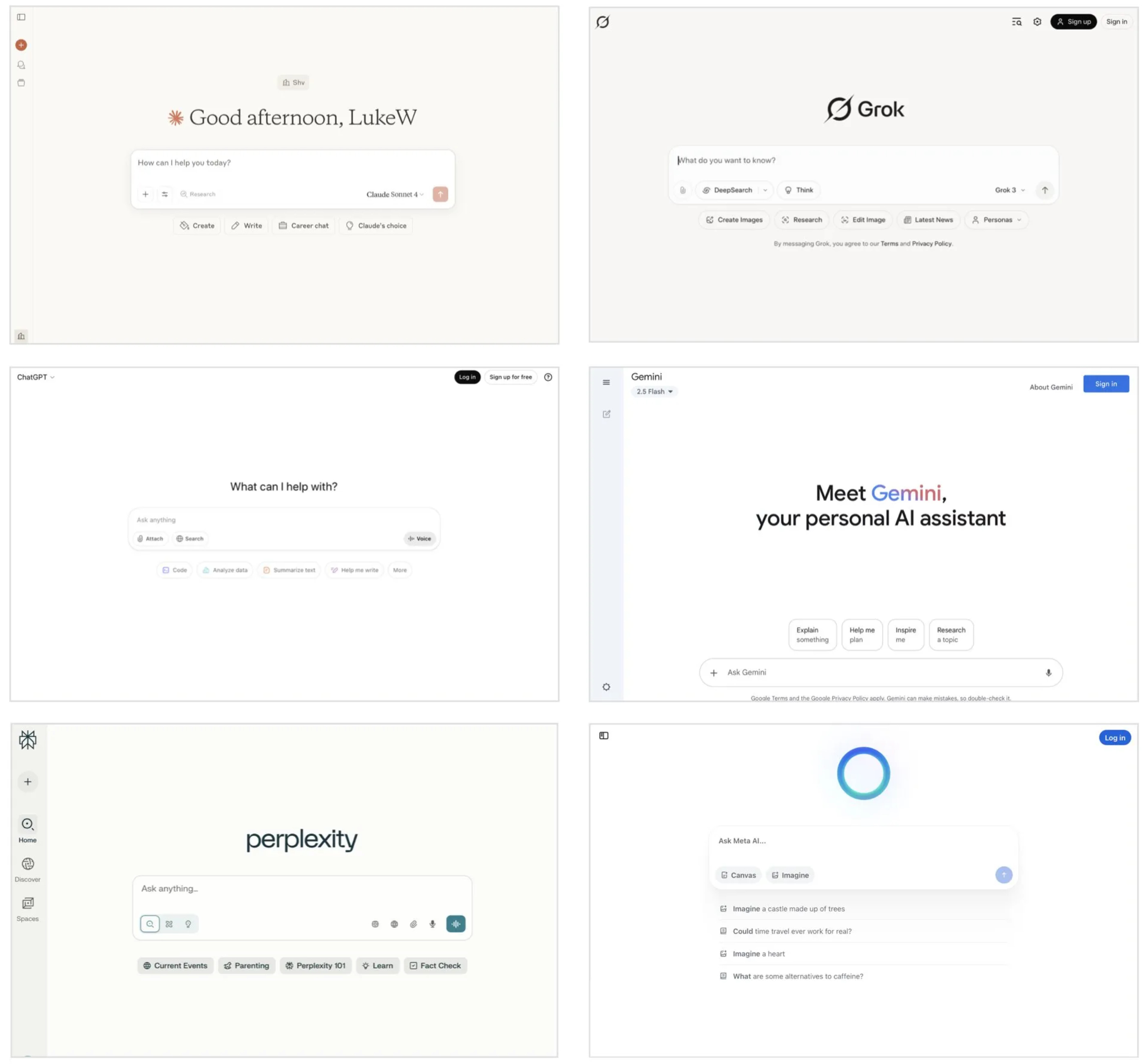
“Whoa, that’s a big statement”, you say. Okay, let’s back up for a second.
All the founder-CEOs are writing internal memos1 to their staff to become “AI fluent”. A working definition of AI-fluency is conspicuously missing, but no matter — these memos are meant more to be missives than tactical marching orders. From my conversations with folks on the receiving end, it boils down to one of two things: (a) those who can, start using tools like Lovable, v0, Replit, Bolt, Cursor to build something to show, and (b) the others download the ChatGPT or Claude or Gemini app to throw everything at it and see what comes back.
For practical reasons, let’s limit our concerns to (b): the less-technical users and uses of LLMs. They’ve been given a search-engine-like text box that orients people to asking short, high-level, complex questions that leaves the LLMs guessing as to what exactly is needed. And guess it does, trying to find the most probably answer from the trillions of documents in its training data, which is a bit like saying “assume I’m the average of the billions of people online, facing an average of zillions of situations you could encounter, find me the average answer that I would consider satisfactory.” That it can write a coherent response is in itself remarkable, but rarely works to the level where it does justice to its super-intelligence capabilities. That’s because you-the-user have specific objectives, with specific constraints and a specific situation that you simply haven’t communicated to the model.
This Redditor has felt the pain: “After 147 failed ChatGPT prompts I had a breakdown and accidentally discovered something”. His secret? He has a meta-prompt that, in essence, asks ChatGPT to identify vague requests and keep asking HIM questions until it has all the information it needs to be able to do the job perfectly. That post blew up on Reddit, highlighting what I’ve said above — most of us simply aren’t writing the right prompts or giving it the right context. And that’s partly because these chat interfaces aren’t designed to make it easy.
While we instinctively know that the word “prompt engineering” grossly undersells and oversimplifies the skills required to make LLMs sing, leave it to the guy who coined the term Vibecoding to break it down for us:
+1 for "context engineering" over "prompt engineering".
People associate prompts with short task descriptions you'd give an LLM in your day-to-day use. When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step. Science because doing this right involves task descriptions and explanations, few shot examples, RAG, related (possibly multimodal) data, tools, state and history, compacting... Too little or of the wrong form and the LLM doesn't have the right context for optimal performance. Too much or too irrelevant and the LLM costs might go up and performance might come down. Doing this well is highly non-trivial. And art because of the guiding intuition around LLM psychology of people spirits.
On top of context engineering itself, an LLM app has to:
break up problems just right into control flows
pack the context windows just right
dispatch calls to LLMs of the right kind and capability
handle generation-verification UI/UX flows
a lot more - guardrails, security, evals, parallelism, prefetching, ...
So context engineering is just one small piece of an emerging thick layer of non-trivial software that coordinates individual LLM calls (and a lot more) into full LLM apps. The term "ChatGPT wrapper" is tired and really, really wrong.

Engineering teams building complex workflows know all this already, and invest in a great amount of tooling: data pipelines, retrieval systems, evals, testing, self-healing steps…
For the rest of us, here are some tactics that can hugely amplify the quality of your output from LLMs, whether you’re using them to write better emails, more compelling marketing copy, better catalog descriptions, create posters, learn new concepts, get coaching on recorded sales calls, find leads, compare products, summarize feedback of a demo, get feedback before doing the demo, etc.
What follows is a long, rapid-fire list, approximately in order of importance (approximate as in point 2 is more important than point 20, but may not be more important than point 4). The way to read this list is to skim quickly through it, and then fire up multiple LLM windows (or prompthq.run) and TRY each suggestion out.
1. Run LLMs head-to-head
Every LLM has slightly different DNA resulting in not only different style and substance but also latency and costs. For example, the Gemini models are prone to rambling, while Claude is terse and needs to be coaxed into expounding. They also excel in different areas: Gemini is the best at image and document understanding, GPT 4.5 has a way with words, Claude slices through legalese the best and Grok is excellent with current affairs and news. Send the same prompt to multiple LLMs at once to see these differences. Over time, you will instinctively get a sense for which LLM is best for which job.
2. Master the System Prompt
System prompts aren’t just extras — they act as center of gravity for the conversation. Models are tuned to give more importance to them, over any other part of the conversation. Use them to:
Set expectations: “Don’t be afraid to challenge me”2, “Ask questions until you fully understand my requests”
Define your style: technical vs casual vs formal, whether to use gen-z slang, to include a tl;dr,
Provide information about yourself: “I’m very technical and business-savvy, but have no legal background” or “This is what I’m building and here is my tech stack”
Guide the output format: “Don’t use markdown” or “Use clear headings” or “Bulleted list in order of importance”.
The chat apps bury the system prompt, and there is no way (that I know of) to change system prompts for different kinds of tasks / conversations, which is frustrating. Different models treat system prompts differently, so always test them.
The famous eigenprompt is one of my favorites.
3. Tone is crucial
If you use the popular colloquialism “explain like I’m 5” (or ELI5 as the cool kids say), the model will literally talk to you as if you’re 5 years old. You have to be specific about the level of sophistication you desire in the answer. For example, for technical conversations I will say “I’m an experienced-but-rusty engineer”, and for legal questions I will admit to being a novice and ask it to explain concepts along with its response.
Bear in mind that LLMs mirror the vibe of your prompt — if you are asking the model to be brief but your prompt meanders on, its response is likely ignore your explicit instruction and will similarly meander.
A trick I learnt recently is to ask an LLM to rewrite my prompt to match the voice of the intended audience. “Please reframe this question as if a medical professional wrote it” will go a long way in having the answer be at the level of medical professionals.
4. Invoke public personas
When I’m asking parenting questions, I’ll begin by saying “pretend you’re Emily Oster3”. Or “What would Tyler Cowen4 think” for … well, many things. Referencing cultural touchstones (like Ghibli5 to generate a particular style of anime images) hits the nail on the head faster and easier than trying to explain your intent with a wall of words.
5. Define what NOT to do
Left unchecked, LLMs will make a best guess. And their training makes them lean towards pleasing you. Draw constraints: “Push back if I’m wrong”, “Don’t be deferential”, “Don’t jump to solutions, but give me options”, “Don’t avoid or explain technical jargon”, “Don’t use formatting until asked” — any time you feel like you’re doing work to make sense of the LLM’s output, you should instead figure out how to tailor the output to your liking.
6. Examples > Explanations
LLM absorb directions very well from examples, far better than they do from explicit instructions, which themselves are hard to comprehensively write. Two or three positive and negative examples go a long way, especially for repetitive tasks like writing ad copy, or catalog descriptions.
7. Screenshots and photos
“A picture says a thousand words” hasn’t felt more visceral than when you realize how easy it is to just upload screenshots or photos to LLMs as context. I uploaded screenshots of every screen of Turbo Tax while doing my taxes this year to make the process much simpler, faster, more accurate and possibly saved6 more in taxes than had I not.
8. You’re providing too little context
You wouldn’t toss vague tasks to an intern — don’t do it to an LLM. Prepare your prompt: provide background, upload relevant documents, clarify your goal, break tasks into subtasks, let the LLM ask questions. A well-prepped LLM (and intern) delivers far better results.
This is why the Google-esque screens above are not well-suited for using LLMs effectively.
9. You’re providing too much context
It is possible to err on the other side too. Modern LLMs can take in 1M tokens7 of context. It is tempting to dump everything you have and hope for the best. Drew Breunig has an excellent article describing the pitfalls: How Long Contexts Fail. He describes 4 failure scenarios: Context Poisoning, Context Distraction, Context Confusion and Context Clash. Worth reading this, and the follow-up How to Fix Your Context.
As I’ve said multiple times: Test everything. Test your context too, increasing it, decreasing it, to see what works.
10. Divide and Iterate
Don’t try to single-shot complex tasks. Break them down, and lead the LLM down the sequence iteratively. I was recently revising a privacy policy. A simplistic way might have been to give the LLM my privacy policy along with another privacy policy that I liked, and ask it to apply the positive aspects of the latter to the former. Instead, I did the following, step-by-step:
“What makes for a good privacy policy? When evaluating one, what criteria would you use?”
“Here’s a privacy policy I found. Can you critique it based on the above criteria? Then create a table of pros / cons. Feel free to add new criteria if you missed any earlier”
“Now here’s a policy I’ve drafted. Can you evaluate it similarly? Tell me where it lacks vis-a-vis the other policy”
This approach works very effectively. It also helps you be much more prepared when using your lawyer’s time to finalize such documents.
11. Start a new chat
Conversations that get too long get unwieldy for the LLM. Any previous wrong turns continue polluting the context and confusing the LLM. If you find yourself saying “try again”, it’s better to start with a new conversation. Ask the LLM to summarize your previous instructions in the old chat, and copy those over as a jump-off point for the new conversation, so you’re not starting from scratch.
Sometimes, the LLM just needs to traverse a new path down the probability tree of possible tokens.
12. Start many chats
Another way to iterate while avoiding long, unwieldy conversations is to have different chats in parallel about different sub-tasks. Solve each individually, and then bring the final outputs together in the a single chat to synthesize. I almost always do this with complicated research or complex technical questions.
13. Read the thought process
When using “thinking” models, read their thinking output closely — this is sometimes hidden in the apps. The thought process offers great insight into the LLM’s logic: what assumptions it made, why it drew certain conclusions, what points it connected. These are extremely useful in knowing how to course-correct and improving your prompt / context.
14. LLMs can fix your prompt
When you’re not getting what you want from the LLM, tell the LLM where its falling short and ask it how to rewrite the prompt to get what you need. It’s usually better to use the more powerful models — Sonnet / Opus / o3 / Gemini 2.5 Pro — for this. LLMs are good at writing and this makes them good at writing prompts too. Always test the prompts they generate side-by-side.
15. LLMs can prepare your prompt (and context) too
Bringing together some of the points made above, collaborate with the LLM in defining the task from the get-go. Give it your goals, ask it what information it needs, what assumptions should be clarified, ask it for multiple plans you can choose from, request sub-task breakdowns. Once you start using LLMs more and more, you’ll see you can use them as collaborators on literally everything, including on using LLMs!
16. LLMs-as-judge
LLM-as-judge is a well known concept used by engineering teams building agents, multi-step workflows and evals. Pass the output from an LLM to another LLM for judgement: “Critique this, and offer suggestions to improve” is a powerful way to get LLMs to improve on each other’s work.
Google trained us to accept the first result, and we have to break that habit.
17. LLMs-as-sparring-partners
Having a second pair of eyes on our work is always helpful, and making LLMs that second pair is relatively frictionless. I never have LLMs ghost-write for me to preserve authenticity. But I freely send it walls of text, near-incoherent ideas, screenshots of slides, pitch or negotiation angles to critique or to simulate an audience reaction, or just to sharpen my own thinking.
We’re not working along any more.
18. Use third-person for brutal honesty
LLMs are trained to please users. Remove yourself from the prompt — present your ideas or work or situations as someone else’s and you’ll get less flattery and more candor.
19. Know when to turn off History
OpenAI launched History in ChatGPT recently, a feature that learns your style and preferences and inserts it as context for all conversations. And other apps are following suit. Sadly, not only does History often infer things incorrectly or misplaces importance, starting with a blank slate can actually be beneficial for many chat sessions. Become familiar with turning history on and off as you need it. It used to be possible to see the actual preferences ChatGPT had derived.
20. Check for hallucinations
This is a well-known problem, and also one LLMs have gotten better at. Simple prompt-based mechanics go a long way in leveling up trustworthiness of their output. “Are you sure?”, “Double check this”, “Cite sources”, “Rate your confidence level” help avoid expensive fabrications. Using another LLM to judge also helps.
21. Compare latency and cost
When automating tasks or using tools like Zapier, n8n, you likely care about latency and costs of LLM cals. Always compare LLMs head-to-head with the same context and you’ll often be surprised by what you find. Gemini 2.5 Pro is priced cheaper than Sonnet, Opus and o3, but ends up costing more per task because of the large number tokens it consumes and generates, for the same task. ChatGPT’s o-series models generate a lot of thinking tokens and it can help to set their “thinkingEffort” parameter to “low”. GPT 4.1 has very high latency. Becoming familiar with these quirks can help you become a power user.
Using LLMs sub-optimally is missing out on the greatest advantage technology has delivered into our hands since fire. That said, I claim merely to be good at using LLMs, not great, so if you have tips to share back, please leave a comment!
www.promptHQ.run is an amazing tool to test prompts and LLMs and get the proverbial fire roaring.
Are these CEO memos truly internal if they immediately post it online?
For some reasons LLMs have been trained to be very obsequious. Ever had one reply to a suggestion from you with “You’re absolutely right!”?
Emily Oster is an economics professor who has created the best resource for new-ish parents that I know of: parentdata.org
Using ChatGPT to recreate images and photos in the style of Studio Ghibli, the famous Japanese anime movie studio, became a viral trend the day their new image model dropped.
This is not tax advice.
One million tokens is equivalent to 2500-3000 printed pages, or 8-10 books!